How to use Google OCR text?
The most popular search engine throughout the world has now sponsored OCR software, which can perform OCR functions on digital images. However, this feature is not yet available on Google docs but you can test it through this link- http://googlecodesamples.com/docs/php/ocr.php
Google re-released Tesseract OCR - an optical character recognition tool into open source. The reason why Google refers to it as a ‘re-release’ is because Tesseract wasn’t originally created by Google. It was developed by Hewlett & Packard between the years 1985 and 1995, back then it was considered one of the top 3 OCR applications in the market for image conversion.
Functionality
It seems to be a rather easy-to use OCR tool. All you have to do is
1. Choose the file you want converted.
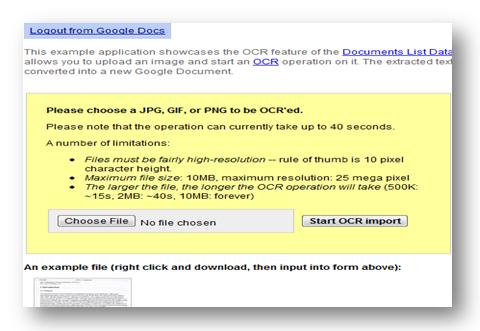
2. Slect ‘Start OCR import’
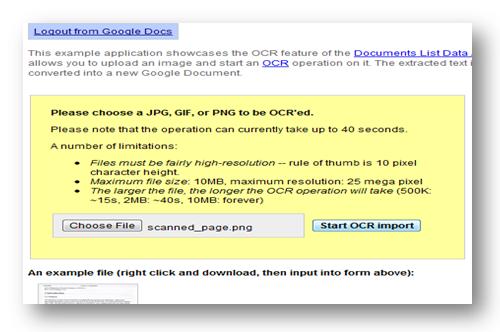
3. Your image is converted and trancfered to google Docs and is ready to be shared, edited and saved.
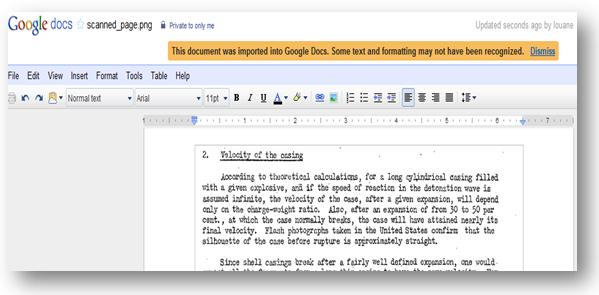
Google docs OCR aims for 100%accuracy, but achieves close approximation. But, considering it is a free open-source OCR it is extremely efficient. The main goal of Google was to make information freely available to people whether it was on a piece of paper or on a computer. The medium didn’t matter; all that mattered was accessibility and availability.
Google aimed at making information available to users whether this information is in a paper document or not. With Google’s optical character recognition initiative, image conversion into text which can be used for indexing is made easily accessible and rapid.